글을 시작하며..
글의 순서
- Norm 이란?
- L1 Norm
- L2 Norm
- L1 Norm과 L2 Norm의 차이
Norm이란?
Norm은 크기의 일반화로 벡터의 크기(혹은 길이)를 측정하는 방법입니다. 두 벡터 사이의 거리를 측정하는 방법이기도 합니다.
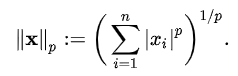
여기서 p는 Norm의 차수를 의미. p = 1이면 L1 Norm. p = 2이면 L2 Norm. n은 해당 벡터의 원소 수.
L1 Norm
L1 Norm은 p가 1인 Norm입니다. 공식은 아래와 같습니다.
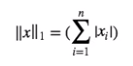
L1 Norm은 맨허튼 노름(Manhattan norm)이라고도 합니다. L1 Norm은 벡터의 요소에 대한 절댓값의 합입니다.
L1 Norm은 다음과 같은 영역에서 사용됩니다.
- L1 Regularization
- Computer Vision
계산되는 방식은 아래와 같습니다.

L2 Norm
L2Norm은 p가 2인 Norm입니다. L2 Norm은 n차원 좌표 평면(유클리드 공간(에서의 벡터의 크기를 계산하기 때문에 유클리드 노름(Euclidean norm)이라고도 합니다. L2 Norm은 피타고라스 정리를 활용한 것으로 공식은 아래와 같습니다.

L2 Norm은 다음과 같은 영역에서 사용됩니다.
- L2 Regularization
- KNN 알고리즘
- kmean 알고리즘
계산되는 방식은 아래와 같습니다.

L1 Norm과 L2 Norm의 차이

검정색 두 점 사이의 L1 Norm은 빨간색, 파란색, 노란색 선으로 표현될 수 있고, L2 Norm은 오직 초록색 선으로만 표현될 수 있습니다. L1 Norm은 여러 가지 path를 가지지만 L2 Norm은 Unique shortest path를 가집니다.
L1 Norm과 L2 Norm을 시각화하면 아래와 같습니다.

이로 인해 L1 Loss와 L2 Loss의 차이가 발생합니다.
대표적으로는 L1 Loss는 0인 지점에서 미분이 불가능하다는 점이고 추가적으로 L1 Loss가 L2 Loss에 비해 Outlier에 대하여 더 Robust(덜 만감 혹은 둔감) 하다고 표현합니다.
아래는 L1 Norm과 L2 Norm의 코드입니다.
def l1_norm(x):
x_norm = np.abs(x)
x_norm = np.sum(x_norm)
return x_norm
def l2_norm(x):
x_norm = x * x
x_norm = np.sum(x_norm)
x_norm = np.sqrt(x_norm)
return x_norm'인공지능 공부 > 이론 및 파이썬' 카테고리의 다른 글
| [이론 및 파이썬] Numpy(1) (0) | 2021.02.07 |
|---|---|
| [이론 및 파이썬] 확률 및 통계 용어 정리(1) (0) | 2021.01.31 |
| [이론 및 파이썬] 정규 표현식 (0) | 2021.01.30 |
| [이론 및 파이썬] 언더스코어/언더바(_)의 역할 (0) | 2021.01.24 |
| [이론 및 파이썬] 파이썬 숫자판별 함수 정리 (0) | 2021.01.24 |