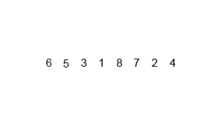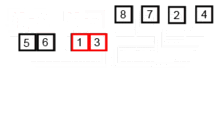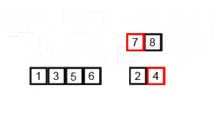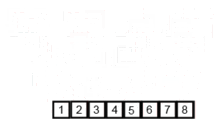스택의 개념
한 쪽 끝에서만 자료를 넣고 뺄 수 있는 LIFO(Last In First Out) 형식의 자료 구조.
스택의 연산
스택(Stack)은 LIFO(Last In First Out)를 따른다. 즉, 가장 최근에 스택에 추가된 항목이 가장 먼저 제거될 항목이다.
- pop() : 스택에서 가장 위에 있는 항목을 제거한다.
- push(item) : item 하나를 스택의 가장 윗 부분에 추가한다.
- peek() : 스택의 가장 위에 있는 항목을 반환한다.
- isEmpty() : 스택이 비어 있을 때에 true를 반환한다.
스택의 구현
문제의 종류에 따라 배열보다 스택에 데이터를 저장하는 것이 더 적합한 방법일 수 있다.
Array 기반 스택
- 접근 속도가 빠르지만 변경이 용이하지 않다.
- 배열이 생성될 때, 메모리의 연속된 공간에 데이터를 저장함 → 검색할 때는 데이터를 빠르게 찾을 수 있지만, 변경이 일어났을 때는 새로운 배열을 생성하고, 생성된 배열에 데이터를 복사해야하기 때문에 느려진다.
- 복사해야할 데이터가 많지 않다면, 크게 상관없지만 데이터가 많아질수록 점점 느려질 것이다.
Linked List 기반 스택
- 메모리 주소를 통해 노드가 연결되어 있어, 배열 기반과 달리 상수 시간에 i번째 항목에 접근할 수 없다. 하지만 스택에서 데이터를 추가하거나 삭제하는 연산은 상수 시간에 가능하다.
- 배열처럼 원소들을 하나씩 옆으로 밀어 줄 필요가 없다.
- 메모리에 연속된 공간에 존재하지 않기 때문에 검색 데이터를 찾기 위해 노드를 순회해야하므로 검색 속도는 좋지 않다.
검색이 자주 일어나고, 등록, 수정 등 변경이 자주 일어나지 않는다면, 배열 스택으로 구현하는 것이 좋다. 반대로 검색보다는 등록, 수정이 빈번히 일어나는 경우에는 연결리스트 스택을 사용하는 것이 좋다.
코드 구현(python)
stack = list()
sp = -1
def stack_pop(stack:list, sp:int):
if sp < 0:
return False
return stack[:sp], stack[sp], sp-1
def stack_push(stack:list, num:int, sp:int):
stack.append(num)
sp += 1
return stack, sp
def isEmpty(sp):
return sp == -1
# idx 호출. 스택 초기화 추가.메모리 스택
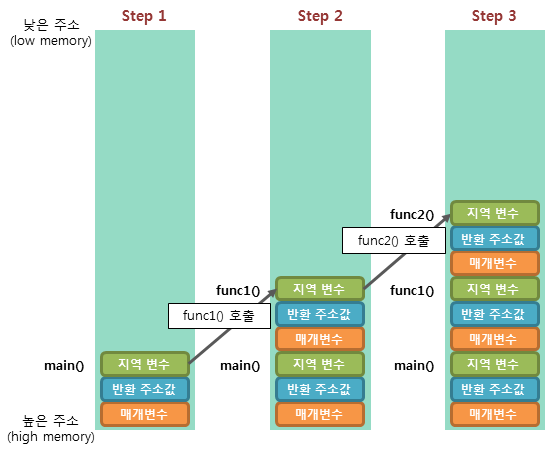
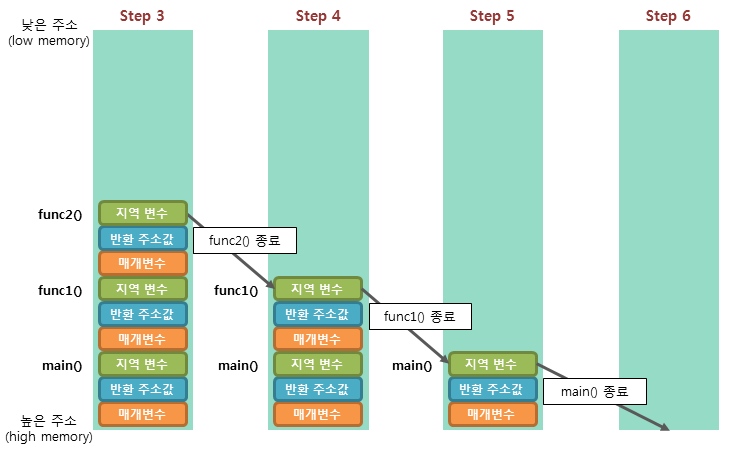
메모리의 스택(stack) 영역은 함수의 호출과 관계되는 지역 변수와 매개 변수가 저장되는 영역이다. 스택 영역은 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸한다.
이렇게 스택 영역에 저장되는 함수의 호출 정보를 스택 프레임(stack frame)이라고 한다. 스택 영역은 push 동작으로 데이터를 저장하고, pop 동작으로 데이터를 인출한다. 이러한 스택은 후입선출(LIFO, Last-In First-Out) 방식에 따라 동작하므로, 가장 늦게 저장된 데이터가 가장 먼저 인출된다.
스택 영역은 메모리의 높은 주소에서 낮은 주소의 방향으로 할당된다.
스택 오버플로우(stack overflow)
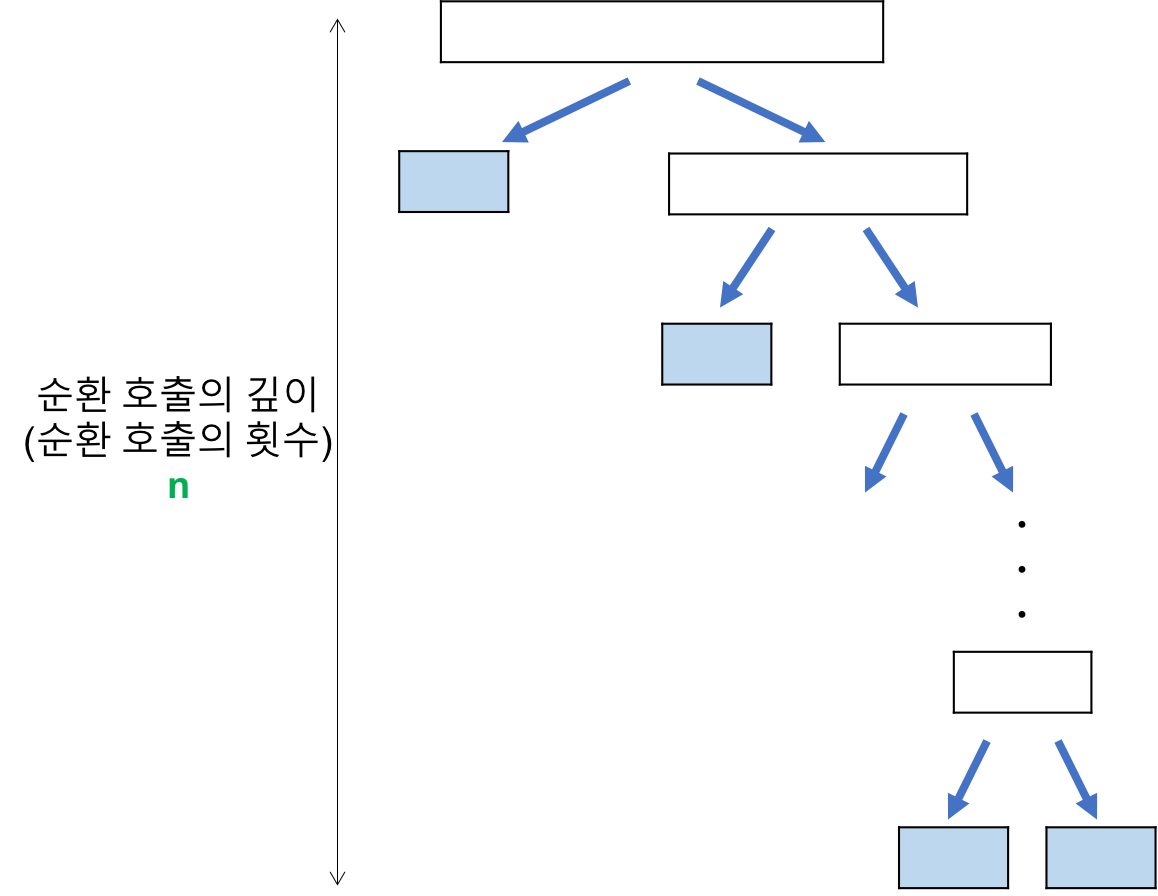
앞서 함수의 재귀호출이 반복되면, 해당 프로그램은 스택 오버플로우(stack overflow)에 의해 종료된다.
만약 재귀 호출이 무한히 반복되면, 재귀 호출에 의한 스택 프레임이 계속해서 쌓여만 갈 것이다.
이렇게 스택의 모든 공간을 다 차지하고 난 후 더 이상의 여유 공간이 없을 때 또 다시 스택 프레임을 저장하게 되면, 해당 데이터는 스택 영역을 넘어가서 저장되게 된다.

이렇게 해당 스택 영역을 넘어가도 데이터가 저장될 수 있으면, 해당 프로그램은 오작동을 하게 되거나 보안상의 큰 취약점을 가지게 된다.
따라서 스택 오버플로우가 발생하면, 에러를 발생하고 곧바로 강제 종료시킨다.